%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# 3D Animation
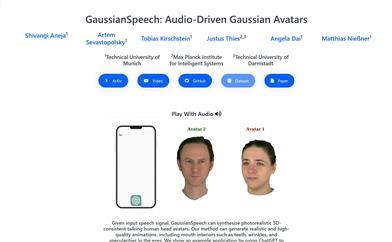
Gaussianspeech
GaussianSpeech is an innovative method capable of synthesizing high-fidelity animated sequences from speech signals to create realistic, personalized 3D head avatars. The technology combines speech signals with 3D Gaussian drawing techniques to capture human head expressions and detailed movements, including skin wrinkling and finer facial motions. Key advantages of GaussianSpeech include real-time rendering speed, natural visual dynamics, and the ability to exhibit a variety of facial expressions and styles. The underlying technology involves the creation of large-scale, multi-view audio-visual sequence datasets and the development of audio conditional transformation models that can directly extract lip and expression features from audio input.
Video Production
51.6K

Vmotionize
Vmotionize is a leading AI animation and 3D animation software capable of transforming videos, music, text, and images into stunning 3D animations. The platform offers advanced AI animation and motion capture tools, making high-quality 3D content and dynamic graphics more accessible. Vmotionize revolutionizes the way independent creators and global brands collaborate, enabling them to bring their ideas to life, share stories, and build virtual worlds through AI and human imagination.
AI video generation
69.3K

Drawingspinup
DrawingSpinUp is an innovative system that converts single character drawings into 3D animations. This technology addresses the challenges of amateur character drawings in appearance and geometry by removing view-dependent outlines and re-rendering along with a skeleton-based refinement deformation algorithm. It not only enhances the visual quality of character drawings but also breathes dynamic life into them, allowing for free rotation, jumping, and even street dance performances.
AI animation generation
56.9K

Animate3d
Animate3D is an innovative framework for generating animations for any static 3D model. Its core ideas include two main parts: 1) Propose a new multi-view video diffusion model (MV-VDM) based on multi-view rendering of static 3D objects and trained on our large-scale multi-view video dataset (MV-Video). 2) Introduce a framework combining reconstruction and 4D score distillation sampling (4D-SDS) that utilizes multi-view video diffusion prior to animate 3D objects. Animate3D enhances spatial and temporal consistency through the design of new spatiotemporal attention modules, and maintains the identity of static 3D models through multi-view rendering. Additionally, Animate3D proposes an effective two-stage process for generating animations for 3D models: First, it directly reconstructs motion from the generated multi-view video, and then refines appearance and motion through the introduced 4D-SDS.
AI video generation
97.7K

SC GS
SC-GS is a novel representation technique that utilizes sparse control points and dense Gaussian functions to represent the motion and appearance of dynamic scenes, respectively. It learns a compact 6-degree-of-freedom (6DOF) transformation basis using a small number of control points, which can be locally interpolated through weight interpolation to obtain a motion field for the 3D Gaussian function. By employing a deformation MLP to predict the time-varying 6DOF transformation for each control point, the method reduces the complexity of learning and enhances its capacity, achieving coherent spatiotemporal motion patterns. Simultaneously, it conjointly learns the 3D Gaussian function, the canonical space positions of the control points, and the deformation MLP to reconstruct the 3D scene's appearance, geometry, and dynamics. During training, the position and number of control points are adaptively adjusted to suit the motion complexity of different regions. A constraint loss function that enforces spatial continuity and local rigidity is also adopted. Thanks to the explicit sparsity of the motion representation and the separation of appearance, this method enables user-controlled motion editing while preserving high-fidelity appearance. Extensive experiments demonstrate that the proposed method outperforms existing approaches in new view synthesis and high-speed rendering, and supports novel applications of user-controlled motion editing with preserved appearance.
AI video generation
54.1K
Move API
_MOVE API is capable of converting videos capturing human motion into 3D animation assets. It supports converting video files to the usdz, usdc, and fbx file formats while offering a preview video. Ideal for integrating into production workflow software, enhancing motion capture capabilities, or creating novel experiences.
AI video editing
129.2K
Synthesizing Moving People With 3D Control
This product is based on a diffusion model framework, designed to generate 3D motion sequences of humans from a single image. Its core components include learning priors about the unseen parts of the human body and clothing, and rendering new body poses with appropriate clothing and textures. We train the model in the texture map space to make it invariant to pose and viewpoint, thus more efficient. Additionally, we develop a diffusion-based rendering pipeline controlled by 3D human poses that produces realistic human renderings. Our method can generate image sequences that align with 3D pose targets while visually resembling the input image. The 3D control also allows for generating various synthetic camera trajectories to render human figures. Experiments demonstrate that our approach can generate image sequences of continuous motion and complex poses, outperforming previous methods.
AI image generation
55.8K
Featured AI Tools
English Picks

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
50.0K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
45.5K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
43.3K
Chinese Picks

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
43.6K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
45.8K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
43.3K
English Picks

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
Chinese Picks

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M